前言
上篇講到LLM,這片就來說說裡面很常提到的字「Token」。Token 是語言模型可理解的最小單位,它像積木一樣把長句拆成小塊,讓模型逐一處理。這篇文章用更平易近人的方式解釋什麼是 token、為何 LLM 不直接處理完整的字詞,以及常見的斷詞方法,幫助你輕鬆掌握這個看似陌生卻無所不在的概念。
Token 是什麼?為何要用它?
LLM 是數學模型,必須把文字轉成向量才能運算。最簡單的做法是把每個單詞賦予一個向量,但這樣會遇到兩個問題:
- 無法處理新詞或拼錯字:如果訓練時沒有見過某個單字,模型就不知道如何表示它。
- 忽略語素結構:許多語言中,一個詞可以拆成詞根和詞綴,例如「running」「runner」都來自「run」。
為了兼顧彈性與效率,LLM 會先把輸入拆解成更小的 token。有人將 token 定義是「字、字元或包含標點的組合」。有些文中也強調,token 是模型用來處理文字的原子單位。透過 token,模型得以把複雜的語言拆成固定大小的向量,並對每個 token 指派唯一編號。
幾種常見的斷詞方法
不同 LLM 可能採用不同的分割策略。以下三種是最常見的斷詞方法:
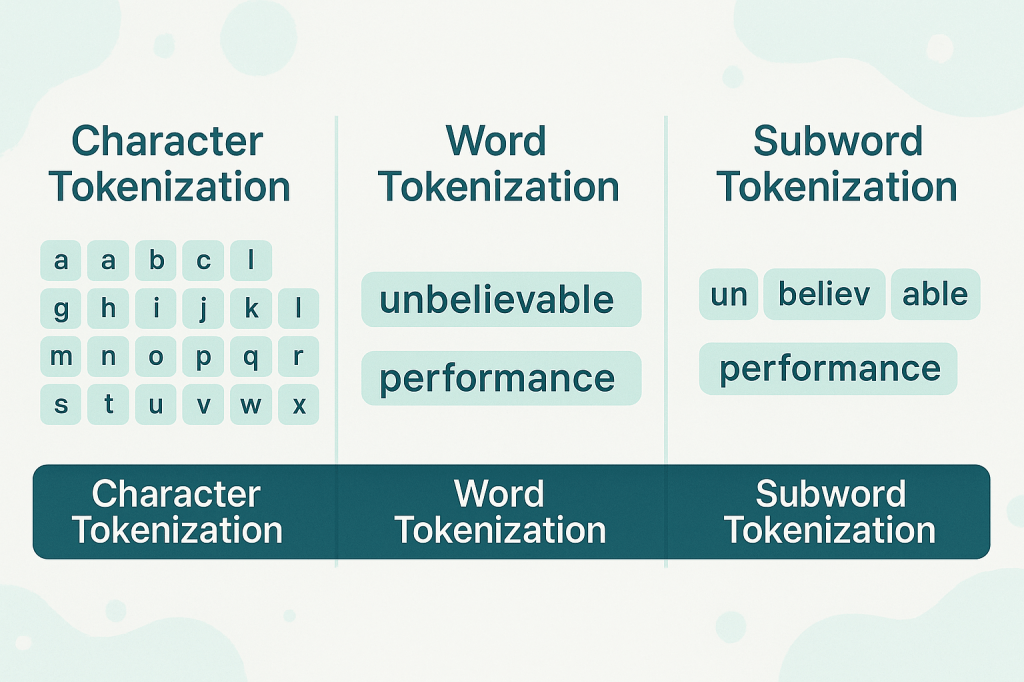
- 字級(Word):按空格切割。例如 “unbelievable performance” 被當作兩個 token。優點是數量少,但遇到新詞就無法處理。
- 字元級(Character):每個字母和空白都是一個 token。它能處理任何輸入,但 token 數大幅增加,效率低下。
- 子詞級(Subword):介於上述兩者之間,把常見詞根或片段視為 token,是現在主流 LLM 的做法。例如 “unbelievable performance” 可以拆成
["un", "bel", "iev", "able", "per", "form", "ance"]。
圖中展示同一句話經過三種方法切分後的樣子:
簡易 Python 範例:手寫子詞切分
以下程式碼示範如何使用簡單的片段詞表(模擬 BPE 結果)把長詞拆成 token。一樣,雖然不是完整的演算法,但能幫你理解 tokenization 的動作。
# 定義一組常見片段
subwords = ["un", "bel", "iev", "able", "per", "form", "ance"]
# 簡易子詞切分函式
def tokenize_subwords(text, subwords):
tokens = []
i = 0
while i < len(text):
match = None
for sw in sorted(subwords, key=len, reverse=True):
if text[i:].startswith(sw):
match = sw
break
if match:
tokens.append(match)
i += len(match)
else:
tokens.append(text[i])
i += 1
return tokens
# 輸入與輸出示範
print(tokenize_subwords("unbelievable performance".replace(" ", ""), subwords))
# 可能輸出: ['un', 'bel', 'iev', 'able', 'per', 'form', 'ance']
每次優先匹配片段詞表中最長的項目,若無匹配則輸出單個字母,呈現出子詞分割的概念。
注意事項
- 上下文長度有限:LLM 的輸入與輸出 token 有固定上限。如果採用字元分割,同樣一段話會產生更多 token,導致可用的輸出長度變短。
- 不同模型斷詞規則不同:GPT-3、GPT-4 可能用 BPE,其他模型可能用 WordPiece 或 SentencePiece;結果不同會影響 token 數量與成本。
- 計價與速率限制:許多雲端服務依 token 數量計費,並對每分鐘 token 數有上限。了解如何計算 token 有助於預估使用成本。
實際應用
在實際應用中,tokenization 是許多 NLP 任務的基礎。以下列出幾個典型場景:
- 文字理解與問答:斷詞讓 LLM 能夠理解句子中詞語的關係,支援資訊檢索與問答系統。
- 文本分類與分析:經過 tokenization 的文本可以餵給分類模型用於垃圾郵件偵測、情緒分析或主題分類。
- 機器翻譯:子詞斷詞能將罕見或複雜的單字拆分,協助模型在源語言與目標語言之間轉換。
- 命名實體辨識:將句子拆成 token 是辨識人名、日期、地點等實體的前置步驟。
- 摘要與聊天機器人:Tokenization 讓模型把長文件拆成可管理的片段進行摘要,也能在對話場景中快速理解使用者輸入。
結語
Token 是大語言模型能理解和輸出的基本單位。透過適當的 tokenization,模型能在見識有限的情況下理解新詞、處理不同語言並產生連貫的文字。熟悉斷詞方法的差異與限制,能幫助我們更有效率地與 LLM 互動並控制成本。希望這篇文章用更簡潔的方式讓你理解 token 的本質,也幫你在未來使用 AI 時更有概念。

發表留言