
前言 Introduction
如果你最近有用過 ChatGPT、Claude、Gemini,你已經在跟 LLM(Large Language Model)聊天了。這些模型看起來像懂很多、會推理、甚至比朋友還健談,但它們的核心動作其實無比樸實:預測下一個字。
聽起來太簡單?沒錯,但模型規模一大、資料一多、演算法一調整,這個「下一字遊戲」就能演變成看起來像魔法的語言能力。
這篇文章會用工程師看得順、初學者不會暈的方式,把 LLM 的概念、原理與常見應用一次講清楚。
LLM 是什麼?
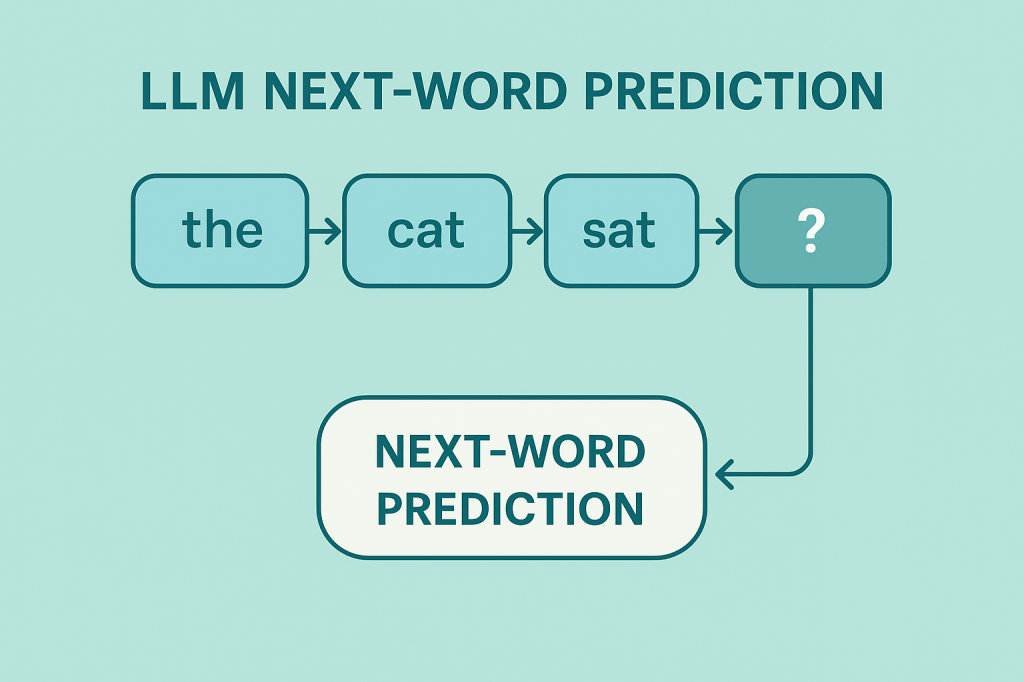
LLM 的任務比你想像的還簡單
從理論上看,LLM 是一種深度學習模型,被訓練去完成一件事情:
在語境下,挑選「最可能出現的下一個 token」。
token 可以是中文字、英文單字的一部分、符號、甚至數字。
當模型知道怎麼選下一個 token,然後不停重複這件事,就能組出一整段看起來像人寫的句子。
為什麼它看起來「懂很多」?
因為它被餵了大量內容:百科、文章、科技文、論壇討論……
在海量語料裡找模式後,它自然會「講得像很懂」。
我們的感官上就感覺它懂很多、很能理解。
LLM 是怎麼「學會」語言的?
LLM 的學習流程大致分成四個步驟,其實蠻務實的:
1. 收集大量文本(資料越多,模型越穩)
來源包含書籍、文章、程式碼、論壇、維基百科等。
資料不是越亂越好,但越多越有機會讀懂語言中的隱性規律。
2. 分詞(Tokenization)
模型不直接處理字,而是處理 token。
你可以把它想像成:「把一個蛋糕切成很多比較好吞的碎片」。
3. 預測下一個 token(核心任務)
模型會計算所有候選 token 的機率:
- 哪個最可能?
- 哪個跟前文最適合?
- 哪個不太會讓模型出糗?
機率最高者 → 輸出。
4. 誤差反向調整(Backpropagation)
預測錯了?
→ 重新調參
→ 再預測
→ 再調
→ 重複幾十億次
這就是 LLM 的訓練人生。
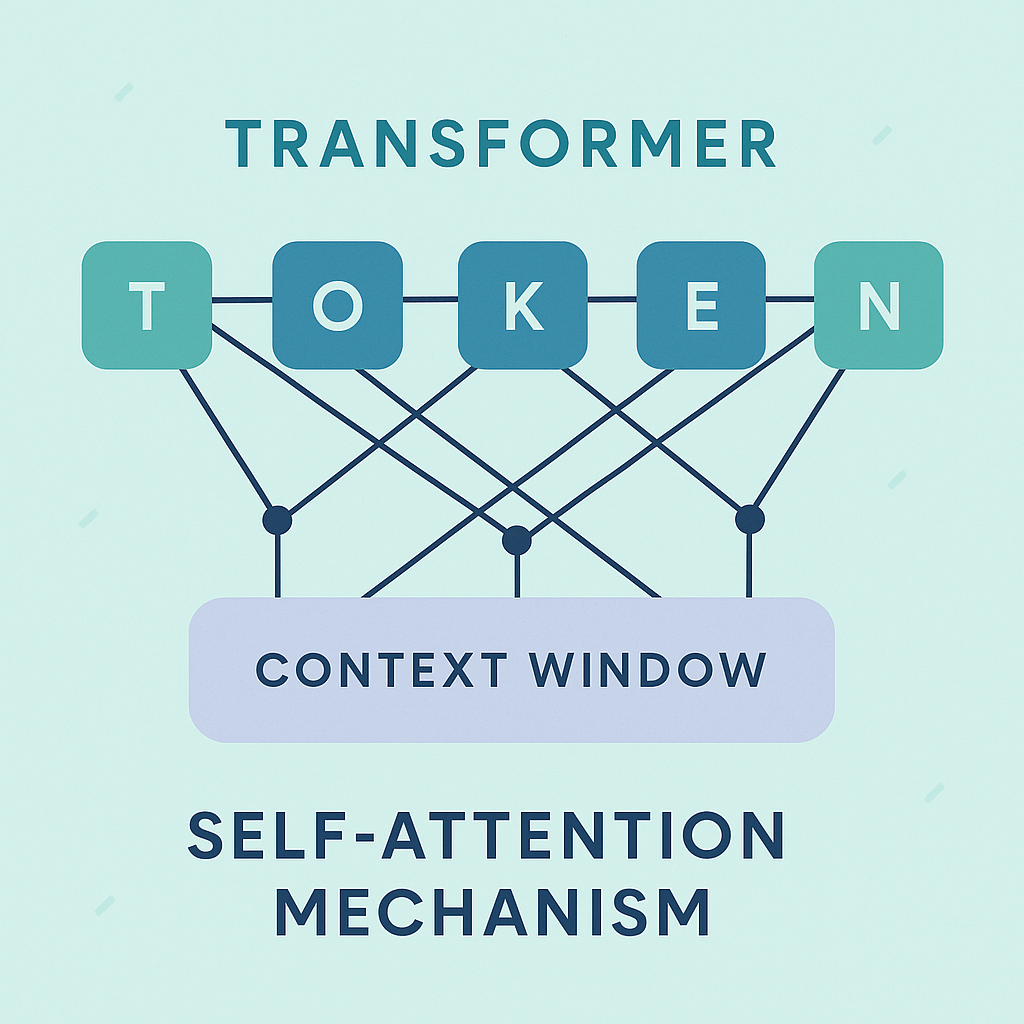
為什麼 LLM 比舊模型聰明?(Transformer 的魔法)
重點只有一句:
Transformer 讓模型能「一次理解整段內容」,而不是從左讀到右。
這也是它比 RNN/LSTM 更成功的原因。
Attention 讓模型可以決定「這句話裡誰比較重要」。
例如:
「我昨天在百貨公司遇到他的媽媽。」
模型要知道「他的」指誰?
Attention 就是用來處理這種依存關係。
LLM 的常見應用
1. 對話生成
你跟 ChatGPT 打字,它回你話,就是 LLM。
2. 自動摘要
幾千字的文章,壓成幾句話。
3. 程式碼生成
模型讀你的描述 → 補出 Python、JS、C++ 等程式碼。
4. 文案/腳本創作
IG 內容、企劃書、劇本、商業信……全都能做。
5. 搜尋強化(Retrieval)
結合資料庫讓模型能「查」不是「猜」。
小示範:一個極簡的「下一字預測」模型(Python)
這不是 LLM,但有助理解它在做的事情。
程式碼用途
示範「根據前文,以最常見模式預測下一個詞」。
import random
# 超簡化版「下一詞預測」
def predict_next_word(text):
dataset = {
"我想": ["吃飯", "睡覺", "休息一下"],
"今天": ["天氣", "工作", "進度"],
"AI": ["模型", "應用", "技術"]
}
key = text[-2:] # 抓最後兩字
return random.choice(dataset.get(key, ["(不知道下一個字)"]))
print(predict_next_word("我想"))
輸出可能結果
- 吃飯
- 睡覺
- 休息一下
行為解釋
當然,這個模型沒有「理解」。
它只是根據常見搭配「猜」下一個字。
LLM 就是把這件事做到極致。

LLM 的限制
- 它不懂世界,只懂資料裡的統計規律。
- 有時會亂講(Hallucination)。
- 語氣、觀點會受到訓練資料影響。
- 對日期、最新事件通常不可靠。
- 無法真正推理,只是推測看起來像推理的下一段內容。
結語
LLM 看起來強大,但核心原理其實異常單純:預測下一個可能的 token。
借助 Transformer、海量資料與超大算力,小小的「下一字遊戲」才能長成今天這個會聊天、會寫程式、會創作的模型。
理解這個本質後,你會更理性地評估它的能力,也更知道如何善用它——而不是被它的「看起來很像懂很多」給騙了。
接下來,也許我們可以一起看看:更多關於LLM的資訊。

發表留言