k-th nearest neighbor
又簡稱KNN,是Supervised learning 的一種,看英文意思很簡明扼要,就是K個最相近的鄰居。
因此這個演算法在實作時,會找到附近K個最近的點,來判斷自己要歸在哪一類。
雖然說他是監督式學習的一種,但是他並不用去訓練參數,而是把資料都儲存起來做資料分類。
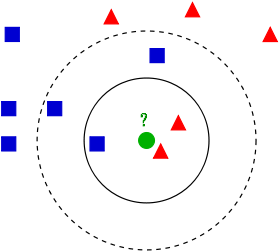
我們可以藉由增加K的數值來增加此演算法的noise margin。
此演算法會有著儲存空間大以及導致空間複雜度高的問題,還有著容易被數據不平衡所影響。
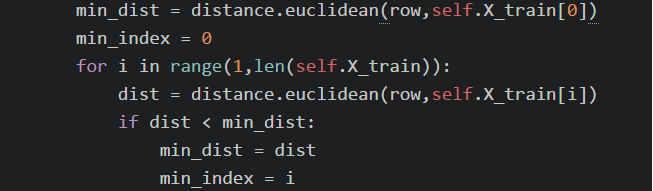
在這個問題的實作上就是算點到點之間的距離,因此我們使用Scipy的函數來實作,為了方便取K值等於1,並且拿來和SKlearn的KNN比較。
想法是用for迴圈來取test data對於每個train data的最近距離,那他就會是最近train data 的 label
準確率
sklearn knn : 0.973333333
手刻 knn : 0.9466666

發表留言