嘗試用sklearn做分析
使用豐原站的觀測記錄,分成train set跟test set,train set是豐原站每個月的前20天所有資料。test set則是從豐原站剩下的資料中取樣出來。
train.csv:每個月前20天的完整資料。
test_X.csv:從剩下的10天資料中取樣出連續的10小時為一筆,前九小時的所有觀測數據當作feature,第十小時的PM2.5當作answer。一共取出240筆不重複的test data,請根據feauure預測這240筆的PM2.5。
sklearn在使用上看起來很直接
因此我們的feature使用最笨的方式:取出所有前九小時的值,甚麼都不做直接看結果。
不觀察feature也不簡化
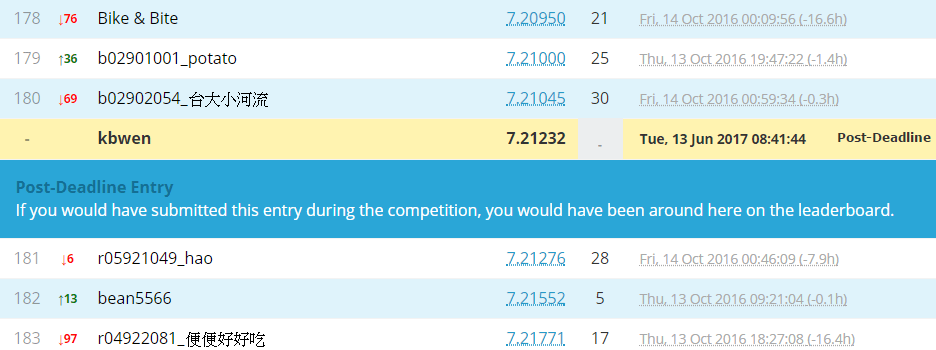
在Private上排名在中間,略高於Baseline
因為是linear regression,對Gradient descent:算一次斜率,結束。
直接就找到解

發表留言